Intro:
For developers of decentralized applications (DApps) that require extracting large volumes of blockchain data, scaling can be a major challenge. Continuous blockchain provider calls can lead to slow loading times, negatively impacting user experience—a crucial element in the success of any Web3 project.
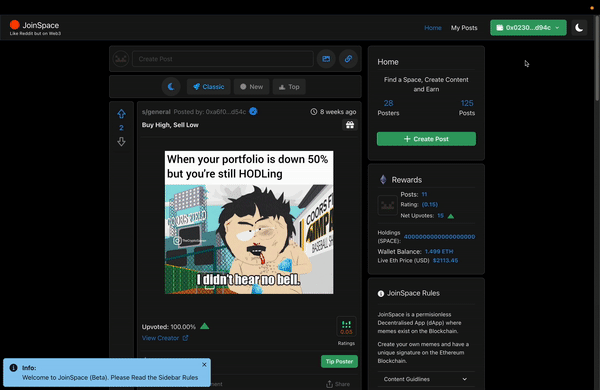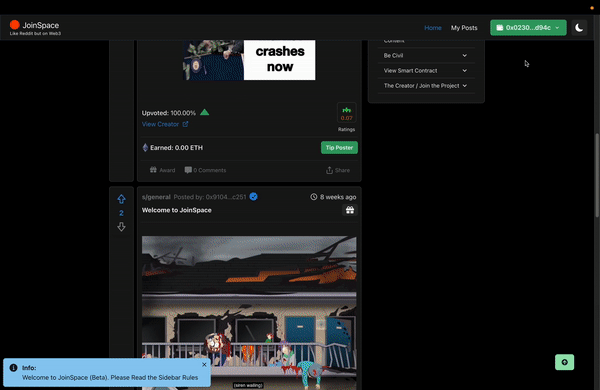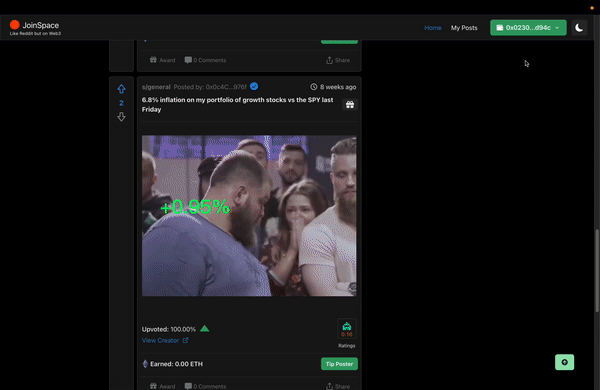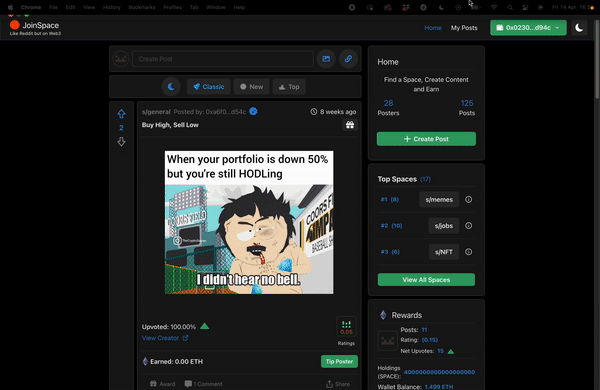
This was the exact issue that was faced when developing JoinSpace (a web3 Decentralized social media) – Note: WebApp is deprecated (in line with Goerli testnet).
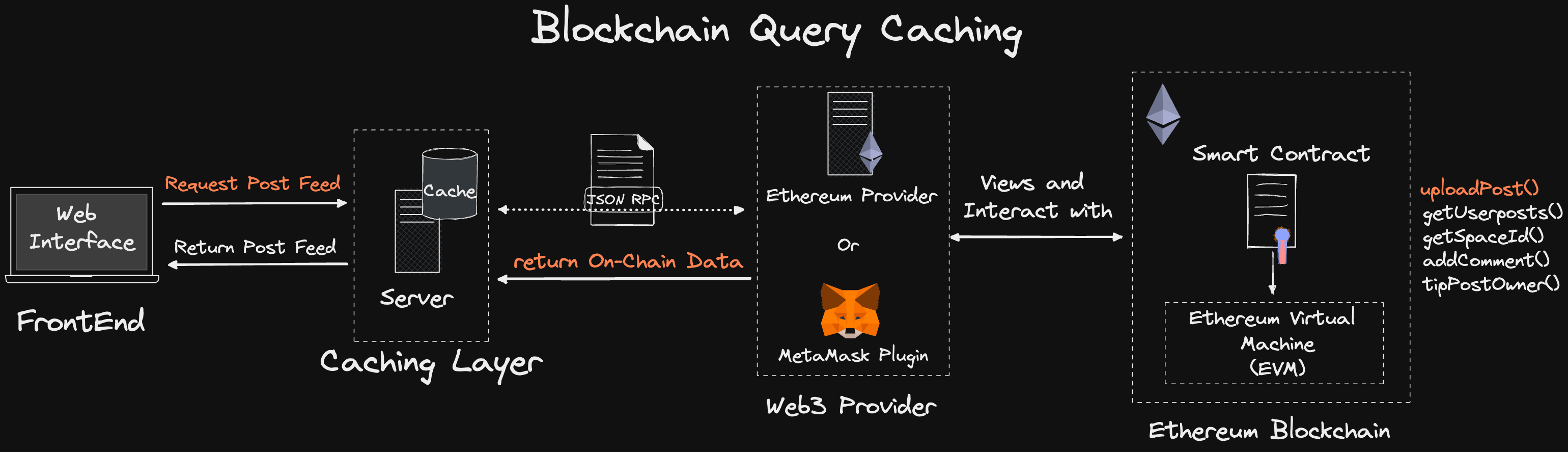
For DApps reliant on heavy blockchain queries (such as a web3.0 social media). Implementing a cache scaling solution (whereby we create a recent in-memory cache of Smart Contract data) is an optimized approach for high-speed data retrieval in order to curate a user’s post-timeline feed.
Using a caching scaling solution further improves the following use cases:
Use Cases:
- Gaming – pull on-chain data, i.e., retrieving ERC721 metadata of a rare sword during gameplay.
- Social Media – curate a timeline feed displaying user’s posts stored on-chain
- Real-time data applications or other data-driven DApps reliant on smart contract queries.
Although we can leverage indexing protocols like TheGraph to query the blockchain. In this article, we’ll look to build a lightweight, simple solution that can accommodate your needs and evaluate the benefits and drawbacks of creating our own Blockchain indexing cache solution.
With the introduction established, let’s dive deep into this article.
DApp Architecture – Reading Data through a provider
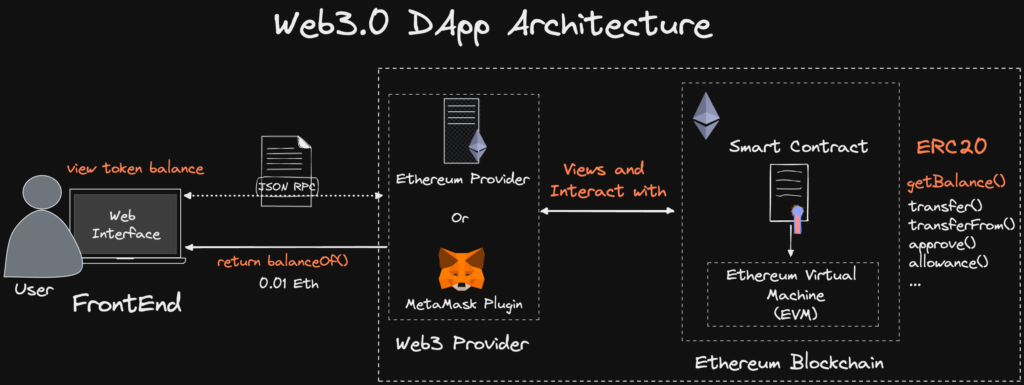
Unlike in Web2, whereby we can query a database by making API calls to the backend server. In Web3, a decentralized application (DApp) requires a provider to read data from the Ethereum Network/ EVMs.
What is a web3 Provider? Simply put, a Web3 provider allows your dApp to communicate with an Ethereum Node. Providers are needed to query the blockchain directly to retrieve on-chain data. Providers take in a JSON RPC request and return a response.
Although anyone can run their own provider, Alchemy and Infura are currently the top node providers used to access the blockchain. These popular providers provide the benefits of high availability, node uptime, and scalability.
JoinSpace Layer 1 Design Decision: Case Study
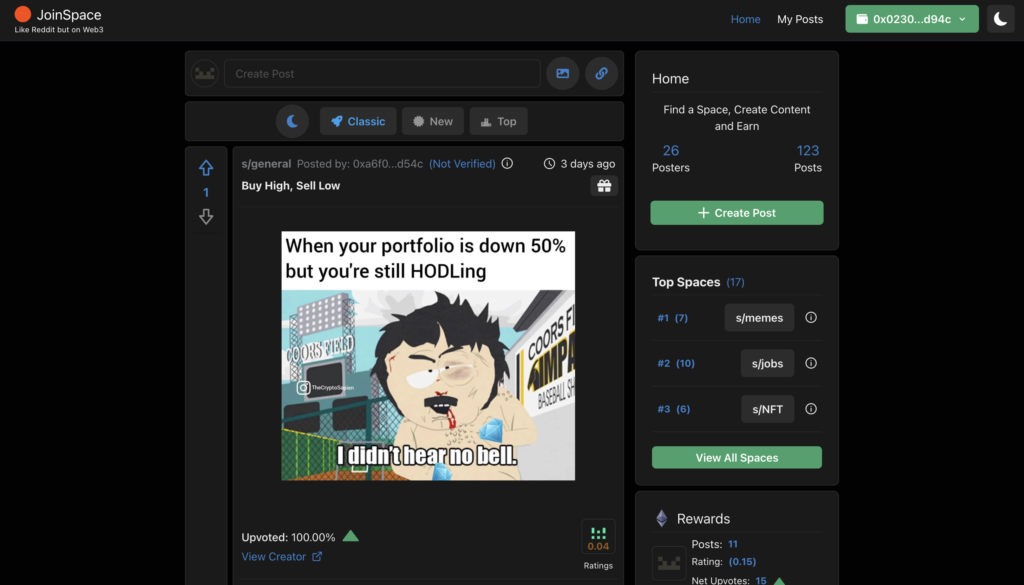
JoinSpace is an experimental web3 social media originally designed to be built on Layer 1. The choice of interacting directly with Smart Contracts was to push the limits of how smart contract(s) could be optimized to store social media “like-data” such as posts, feeds, and comments. (More on Next Steps).
The current design constraint poses an issue with scaling. JoinSpace data, such as posts and comments, are primarily stored on Smart Contracts, meaning the data retrieved from the Blockchain heavily relies on on-chain calls using a provider.
The heavy load of constant calls to the provider and data parsing on the front end has led to poor load performance of post feeds, consequently leading to a bad User experience.
Let’s explore how we can create our own off-chain scaling solution.
The Scalability Issue:
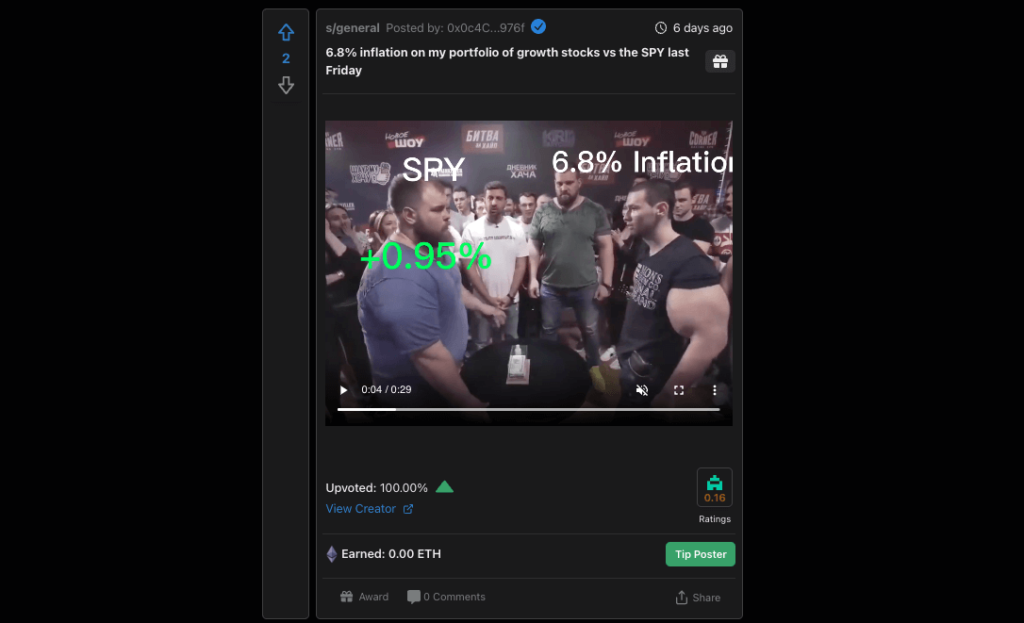
The goal is to retrieve data stored relating to posts, comments, and user interaction from the blockchain. However, Blockchains like Ethereum are not natively designed to serve as a “high-speed database” for complex data queries.
When a user reads data from the blockchain, the user calls the blockchain network/node via an RPC provider and uses a web3 library such as ethers.js to interact with the contract instance.

Heavy Front-End Data Processing The approach of querying directly from the Smart Contract to render a new feed of 100+ posts, Led to a significant reduction in performance on the front end due to the heavy processing load.
In addition to applying further front-end data processing could be better optimized in the backend, such as:
- Converting
block. timestampinto a readableposted: 3 days ago - Querying the IPFS source to render a media image or video
- sorting all posts by a specific query such as
Top posts,New posts
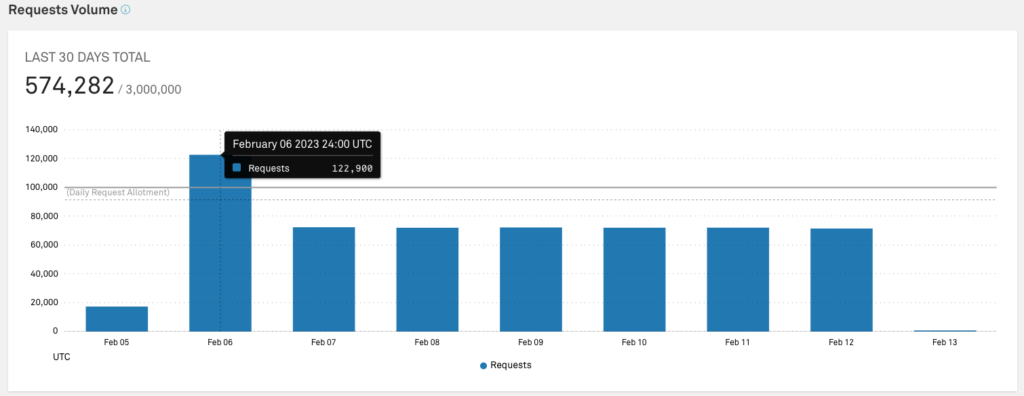
RPC Provider Rate Limits and Query Caps
Further, popular web3 Providers such as Alchemy and Infura have request and rate limits. If we were to serve a single user data directly from the blockchain (on-chain) via a specific provider, we’d make more than 100+ calls to the provider to generate a single home feed. This following logic would have become impractical as we scale to n users.
Further, we run the risk of exceeding RPC request caps, such as (Infura daily limit cap), either costing more to adjust to a suitable pricing model or receive severe rate throttling. Both are bad for UX and scalability.
Connecting a Wallet to preview post – Bad UX

As a social media, we’ll at least also want to include the ability to preview posts, comments, and likes to guests to incentivize a user to sign in or up. Relying on a user to connect their wallet before viewing content would lead to a poor user experience.
Solving Blockchain Scaling Issues with Web3 Caching Layer:
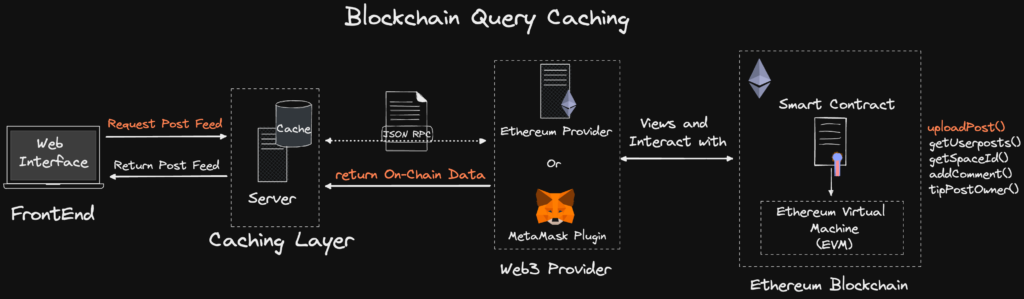
TL;DR: The proposed solution for reducing provider calls is implementing a blockchain caching layer that stores an up-to-date/ sync copy of the blockchain-queried data.
Whereby instead of the dApp querying the blockchain directly to request data on every page reload. The caching layer queries the blockchain (on behalf of the Dapp), caches the latest blockchain call, and the Dapp interacts with the caching layer via REST/GraphQL APIs.

The end result is that the DApp calls to retrieve the data via an API rather than directly on-chain, whereby the cached data would be identical to the data read through the Provider.
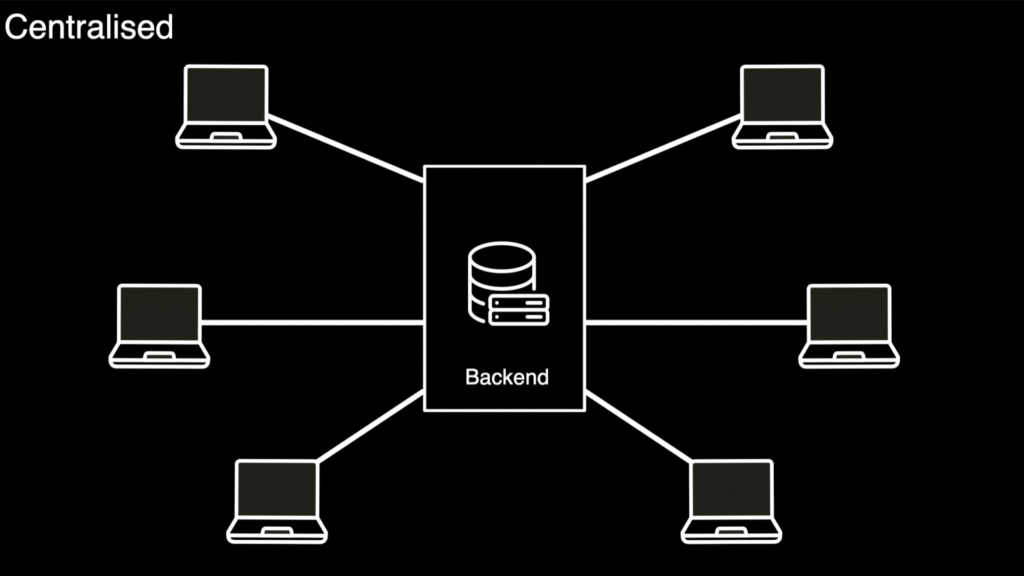
With that in mind, let’s detour to web2 architecture to get a better understanding.
A Typical Web2.0 Architecture
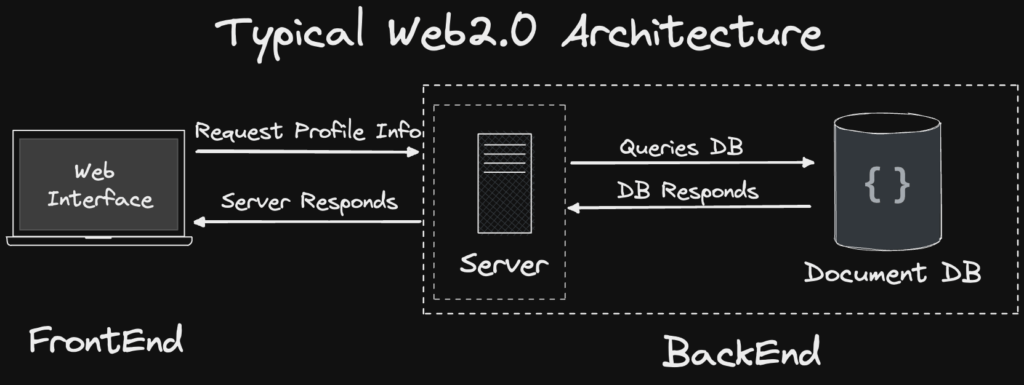
Similar to an Indexing Layer such as TheGraph. We’ll create a subset of cached data calls to interact with, whereby in our case, we’ll store data on an in-memory cache.
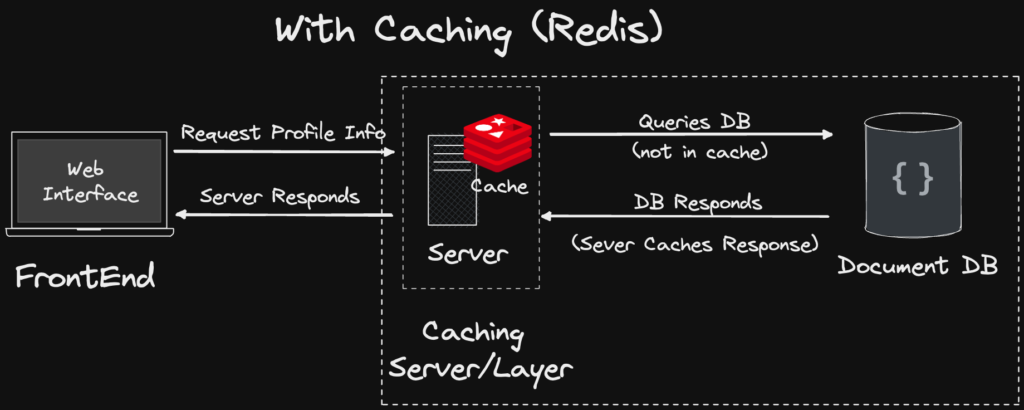
What is an in-memory cache – Redis
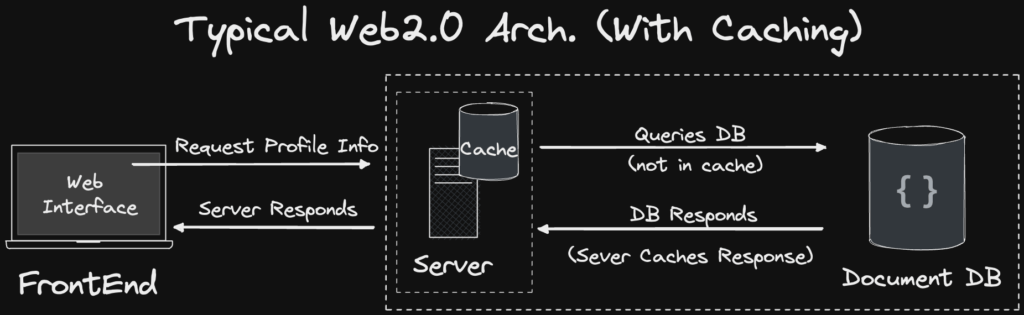
An in-memory cache is a data storage layer that sits between the application and the database to deliver data to the application at higher speeds. This is typically done by storing earlier requests or data copied directly from the database to the cache.
Using an in-memory cache significantly increases performance, given we’re reading off the main memory / RAM. As a result, a caching layer provides faster reads/writes, as opposed to a traditional database that accesses data through Disk Storage.
Note: Choosing an in-memory or a Mongo-like database depends on your design requirements.
…Now, back to web3
The following is a Solidity code snippet of a post struct that represents an individual post instance:
///@notice Struct holding data on a Post
struct Post {
uint256 tipAmount;
uint32 spaceId;
uint32 datePosted;
uint32 upvotes;
uint32 downvotes;
uint32 id;
address payable author;
bool isSpoiler;
bool isOC;
string ipfsHash;
string postTitle;
string creditSource;
}
///@notice Maps the post index to the post data
mapping(uint32 => Post) public post;
///@notice Mapping to get all posts by user address
mapping(address => uint32[]) posts;
Given that posts are regularly fetched on every page load. The post object is an ideal data type to query through the cache.
The in-memory cache temporarily stores all posts by index (postId) relating to the smart contract.
- We’re able to call
getPosts(uint256 postId)for the current post data stored by index on-chain. - We’ll develop an application that can initially iterate through and save the queried data on the cache and updates the in-memory cache on emit/events for new posts/updates.
- The Dapp calls the query data to retrieve up-to-date data via API call. e.g.,
/getPosts/startAt=10&limit=5– returning the first five posts starting from index 10.
This is a significant improvement for scalability, as opposed to making regular and repeatable calls to the blockchain with no caching – leading to intensive RPC calls, duplicate data, and performance issues.
Best of all, a persistent database is not required, such as mongoDB., as the cache is designed to temporary store to reflect the data on the blockchain. This data is regularly flushed/updated on a new contract event.
Architecture- Implementing a web3 Caching Layer:
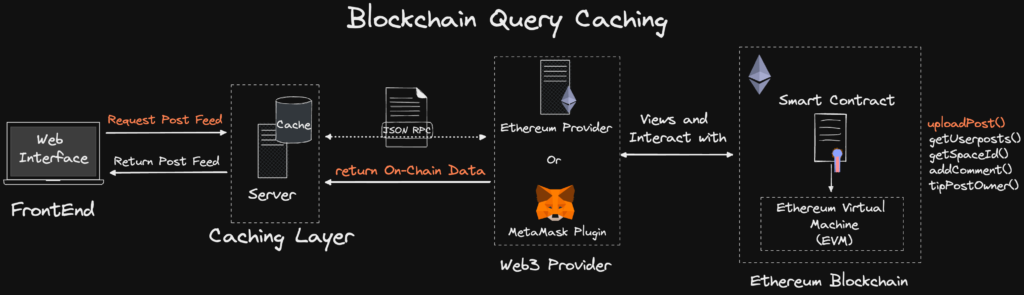
The following outlines the data architecture of how the cache is updated to accurately reflect the data of the posts stored on the smart contract.
There are two main approaches to cache the post data on the smart contract:
- Caching at Intervals – Query the Smart Contract and cache the data retrieved regularly. ****(using a cronjob).
- Blockchain Listeners and Caching – only query the Smart Contract upon a new event change through an invent listener and store the updated value to the cache.
Approach 1: Caching Blockchain Data at Intervals
Although approach 1 is a relatively simple solution, in the event that no new posts have been added to the cache for a while, the cronjob would be making regular calls to the provider regardless of any change to the data.
Further, from a user experience. If a user creates a post, the user would either have to read the post directly on-chain or wait for the next caching interval for the data to reflect on the post feed. Leading to poor UX.
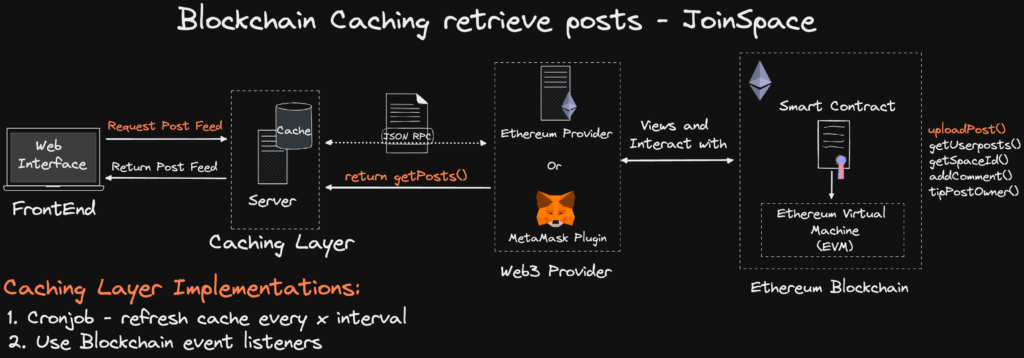
Approach 2: Blockchain Listeners and Caching
The above outlines an overview of how the DApp would interact with the Smart Contract Cache.
Approach 2 is the design decision that was implemented.
Smart Contracts provide the ability to emit an event when a function has been successfully executed. Web3 Libraries like ether.js provide a compact Javascript library to listen to these events and programmatically doSomething() as a callback. Ideally, these Blockchain listeners provide the ability to receive “alerts” regarding new Smart Contract events.
The approach here is upon any changes to the smart contract, such as uploadPost(), upvotePost, addComment , we’ll listen to an emit event on the smart contract and update the cache with the change broadcasted. The data on the cache will now reflect the latest data via a direct blockchain / smart contract query.
This caching layer now lays idle listening and only updates the cache to synchronize with the latest on-chain data without regular cronjobs or intensive RPC calls to generate the post feed. Instead of making 100+ Blockchain calls. We now rely on a cache server to make RPC calls to update the cache only when necessary—querying and updating that specific data that has been changed.
Note: NextJS provides Serverless API Routes, meaning we can interact directly with the Cache via NodeJS Express Server API routes, making for a cleaner solution! The Caching layer could be deployed as a Microservice interacting with the DApp.
Benefits of a web3 Caching Layer:
- Significant reduction in blockchain calls via a provider
- Increased performance in API query requests to retrieve the latest posts.
- Increase performance on front-end data processing
- Users can view on the latest on-chain posts without needing to connect to their wallets.
- Reduced stress on the RPC provider
Optimization Speed and Performance:
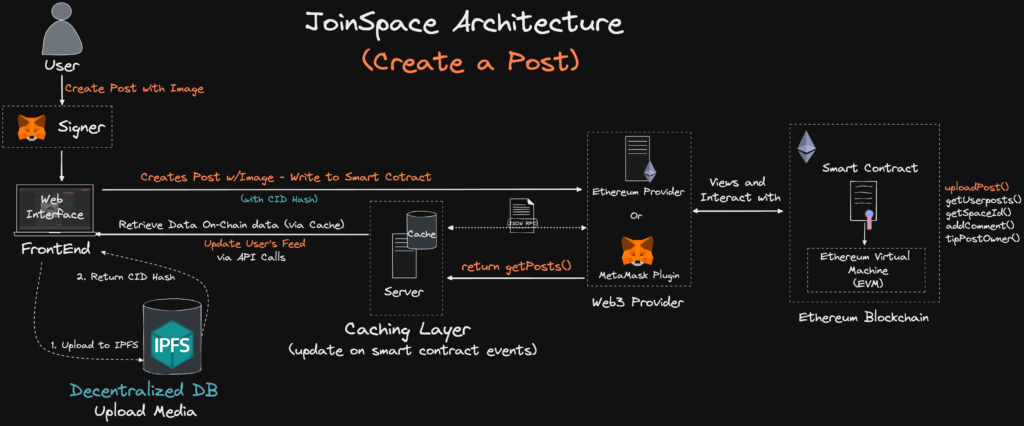
The main overall benefit of a caching solution for JoinSpace is reduced calls to the provider. The implementation of updating the cache based on a new blockchain emit/event to allows the cache only to be updated on the data that has changed (e.g., increment a user's post upvote score of post.id=69 from 39 to 40 ) instead of iterating through and re-caching all the posts stored on the smart contract.
Meaning rather than the DApp interacting with the Blockchain directly. Users would interact with the cache layer via API calls to retrieve the cache data. (as seen JoinSpace Web 3.0 Architecture diagram).
Limitations:
This solution is not the perfect solution. However, caching on-chain data greatly benefits use cases where the application requires constant/ high speed from the Blockchain, such as Gaming, Social Media, and Content Sharing. However, like all implementations, there are some tradeoffs mainly coming down to centralization:
- “Web2.5” – Although we’re reading from the Blockchain. One can say that reading a cached version of on-chain data isn’t fully decentralized, as we’re reading from a centralized cache. – However, the Dapp can also be read directly on-chain via a signer’s provider, e.g., Metamask. as data is open and transparent.
Conclusion:
The implementation of an off-chain caching solution has significantly improved performance for JoinSpace, reducing the need for continuous blockchain calls and lowering costs. This solution is particularly valuable for data-driven DApps like social media platforms and gaming applications that rely heavily on real-time blockchain data.
By introducing a caching layer, we’ve not only optimized data retrieval but also ensured scalability as user numbers grow. While this approach introduces some centralization, the performance benefits far outweigh the trade-offs for applications that require fast, reliable data access.
For more technical insights, follow me on Twitter: @ebenkouao, https://twitter.com/ebenkouao